VCDR – VMware Cloud Disaster Recovery is a service offered by VMware to create a Disaster Recovery solution based on public cloud infrastructure and VMware solutions. The concept is to easily calculate the costs of operating such a DR solution, making it easily scalable, and, perhaps most importantly, easy to deploy and maintain. In my assessment, all these parameters have been met, and VCDR is a very good solution. Additionally, VCDR can address contemporary issues such as ransomware recovery. After a ransomware attack, it’s possible to restore the machine to its state just before the incident. VCDR not only introduces DR implementation in the cloud but also leverages existing, albeit not very commonly used, on-premise solutions, such as fast snapshots (quick in deletion).
I don’t know if it’s an indicator of the complexity of the product, but take a look at the weight of the documentation for this product, and you’ll immediately know that it’s not the most complicated application in the VMware stable – and that’s the whole idea.
To start with the product you don’t really need to know the AWS Public Cloud as well. Very basic knowledge is enough. In addition you will probably have to communicate to VMware that you are going to test/implement that product so it will be visible in VMware Cloud “Cocpit” (or whatever that side is called when you will be implementing that product).
VCDR has many well-thought-out solutions from an architectural standpoint. In my opinion, one of the most important is that during a DR event, there is no need to restore the system to the target SDDC. Resources from CFS (see below) are mounted to physical ESXi hosts, and the mechanism can intelligently power on the requested machines—with a specified date—so that they can essentially run on this storage. Only when they are powered on does the process of migrating them to the target SDDC storage (such as vSAN) take place. This significantly speeds up the system’s start at the moment of failover. It’s worth paying attention to this when choosing DR technology.
Architecture, project design
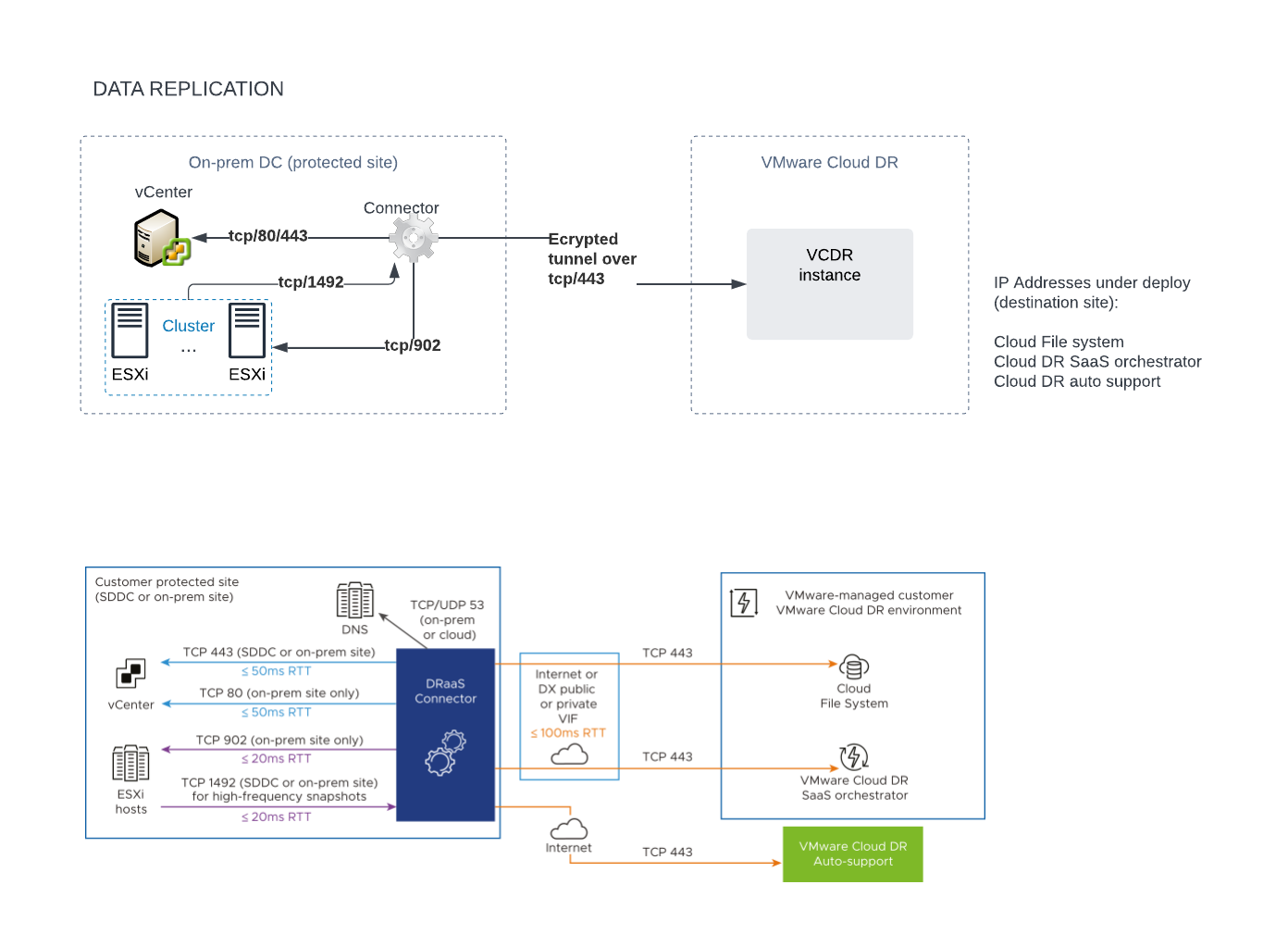
From one side we have protected DC (usually your on-prem DC, but of course it can be VMC implementation as well – or even AVS and other (there were announcements for future implementation)
Bluebox (DRaaS connector) is a product (appliance) that need to be implemented in the source DC (check below requrements). Connector needs from one side of course get access to our local infrastructure, from the other to Cloud File System (CFS) which is implemented in the cloud. From that point of view, DRaaS connector is a crucial component, as it needs to be properly implemented by VMware ifrastructure administrator (together with Network administrator) and at the end it needs to be properly maintained as without that component there DR will not work. It might be good practice to implement more than one connector and plan place/number of connector to your infrastructure (number of cluster, number of management netwoks, etc).
CFS (Cloud File System) – place (hidden S3?) is used to store snapshots from the on-premise DC. Also eventually to restore VM (in some situtation). Can also be use to restore individual files (check systems that are supported). Also backuped images are mounted during DR (real DR situation or testing) in a way, that VMs can be started before it is fully migrated to SDDC datastore (vSAN). More information: https://docs.vmware.com/en/VMware-Cloud-Disaster-Recovery/services/vmware-cloud-disaster-recovery/GUID-085F853C-307E-4D63-ACFB-59586E2FAD8A.html
Cloud DR orchestration – for us, is it nicely working web UI, very intuitive
SDDC on VMC (AWS) – this component is necessary to run our workload in the Cloud (after DR recovery – both, real or during tests). It is important to understand and well design VMC as it not necessarily needs to be up and running all time.
Network communication:
Preparation
Very nice checklist can be found on the following page: https://docs.vmware.com/en/VMware-Cloud-Disaster-Recovery/services/vcdr-predeployment-checklist/GUID-9DFCE5CD-C979-4F48-91ED-D9E241489617.html I guarantee that you will be back to that list at the beginning quite often.
Verify the network requirements and connector resource requirements:


Requirements for AWS:
- AWS account
- Information who is managing and create necessary accesses
- Whether a new internal SR needs to be created before the change, how long does it take
- AWS account must be linked to VMware Cloud organization
- AWS permissions: https://docs.vmware.com/en/VMware-Cloud-on-AWS/services/com.vmware.vmc-aws-operations/GUID-DE8E80A3-5EED-474C-AECD-D30534926615.html#GUID-DE8E80A3-5EED-474C-AECD-D30534926615
- Permission to create VPN (components)
- Permission to create bastion (sandbox) Windows EC2 instance
- AWS account being linked must have sufficient capacity to create a minimum of 15 ENIs per SDDC, in each region where an SDDC is deployed.
- Dedicate a /26 CIDR block to each SDDC and do not use that subnet for any other AWS services or EC2 instances (or on-prem).
Available AWS Regions: https://docs.vmware.com/en/VMware-Cloud-Disaster-Recovery/services/vmware-cloud-disaster-recovery/GUID-4C3DC7CC-6799-4D41-8A15-F09A0DBCF96B.html
In addition it is important to have additional access to the recovered environment when on-prem DC will be unavailable. Implementation can looks like on the following diagram:
In nutshell implementation (when physical/virtual components are in place) looks like on that picture below, and basically that is the screen from the VCDR UI, so you can configure all steps one after another.

- configure API token is fairly easy and well described in UI
- Deploying CFS is fairly simple, most important option is to select proper AWS region (the same where SDDC will be/already is deployed)
- Set up protected side:

In VCDR UI you can find link to download and deploy connector appliance (it is possible to paste url to vCenter when vCenter management network has access to the internet)
- Create protection group, with:
- group of protected VM in one group
- select type of synchronisation
- Add recovery SDDC:

6. Create recovery plan

Monitor replication tasks and in general the solution.
It is extremely crucial to conduct tests immediately after configuration. The most important tests will revolve around performing a test failover and a full failover. Subsequently, also testing the return with switched-on VMs to the on-premises data center. It should be noted that while failing over to the SDDC is an emergency situation and it is the administrator’s responsibility to ensure that the source DC is not functioning correctly and systems are unavailable, in the case of a return, it is a planned action. Systems in the SDDC should be powered off and migrated during the scheduled downtime.
I’ve worked a bit with this solution, and I must admit that during failovers or returns, I didn’t encounter major issues. The technology worked flawlessly and surprisingly well. Of course, much depends on the operating system, the state of applications, and a well-thought-out test plan to conclude everything as expected. I hope that I’ve been able to help those interested in the technology to some extent, and perhaps I can motivate someone because, as you can see, DR solutions don’t have to be difficult.
You have to remember that VCDR is designed for Disaster Recovery (DR). This means that this technology should be used when our primary data center is not functioning (due to a virus, earthquake, or fire). It is not a backup solution (at least, there are better solutions for regular backups), and it is not a high availability (HA) solution. I wanted to highlight these points because there are situations where they can be confused.

No Comments